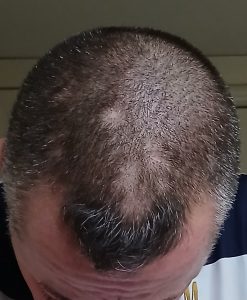
Alopecia Areata
Finally was ramped up to Dermovate (0.05% Clobetasol) which got regrowth but I couldn’t complete the course due it immunosuppressing me too much. I clippered most of the head to also go a melanoma hunting (us UK kids got burnt from childhood in the days of the big Spanish getaway late 1970s, not to mention my 6 years in Sydney spent on beaches so often)!
The big patch on left not as bad it looks – reflects my bad clippering and camera angle! But the regrowth bits are clear.